Post One of Two
1. Introduction
This second part tries to return to reality after I let AI go to town and take my previous post way too far. Too many words, too many functions, and a lot of the SQL doesn’t work. Here I will try to keep it concise and will test all code to ensure it works. Though I don’t promise to stay away from the AI, I’ll just keep it on a shorter leash.
My first goal is to restate the functional aspects of demonstrating linear referencing in PostGIS using the trails use case. So, here is a little recipe restated more concisely from part 1.
Given two input tables (in a schema called blog) produce a single output materialized view (because I haven’t touched mv since my days at Tetra Tech) that represents the linear refrencing concept.
In more words, humans enter points and needed attributes into Input 1, the obs table. obs are referenced to line features in the trails table. We don’t carry any useful human attributes forward from the trails table here (like trail name) but you could. Functional attribuites of obs records is size, but we also have name, desc, and severity rating. The final output segments is created through a series of intermediate queries (DBAs are shaking their heads). These segments are linear features along the trails that represent the size (length) entered in the obs record.
2. Methods and Implementation
So given two input tables that might be created as follows.
-- Input table 1 is called `obs` and is populated by user actions
CREATE TABLE IF NOT EXISTS blog.obs
(
id integer NOT NULL,
geom geometry(Point,6348),
name character varying(50) COLLATE pg_catalog."default",
"desc" character varying(250) COLLATE pg_catalog."default",
severity_int integer,
size_m double precision,
CONSTRAINT obs_pkey PRIMARY KEY (id)
)
and
-- Input table 2 is called `trails`
CREATE TABLE IF NOT EXISTS blog.trails
(
fid bigint NOT NULL,
geom geometry(LineStringZM,6348),
id integer,
osm_id character varying COLLATE pg_catalog."default",
name character varying COLLATE pg_catalog."default",
highway character varying COLLATE pg_catalog."default",
CONSTRAINT trails_pkey PRIMARY KEY (fid)
)
Create a single materialized view.
-- This materialized view combines multiple spatial operations to create segments along trails based on observation points
-- It processes the data through several CTEs (Common Table Expressions) to transform point observations
-- into linear segments along trails, incorporating various measurements and spatial calculations
DROP MATERIALIZED VIEW IF EXISTS blog.mv_segments;
CREATE MATERIALIZED VIEW blog.mv_segments AS
WITH
-- First CTE: Find all trails near observation points within 200m
-- Orders results by observation ID and distance to ensure closest trails are processed first
ordered_nearest AS (
SELECT
ST_GeometryN(blog.trails.geom,1) AS trails_geom, -- Extract the first geometry from MultiLineString if present
blog.trails.fid AS trails_fid, -- Trail feature ID
blog.trails.osm_id AS trails_osm_id, -- OpenStreetMap ID of the trail
ST_LENGTH(blog.trails.geom) AS trail_length, -- Calculate total length of trail
blog.obs.geom AS obs_geom, -- Observation point geometry
blog.obs.size_m AS obs_size, -- Size of the observation in meters
blog.obs.id AS obs_id, -- Observation ID
blog.obs.severity_int, -- Severity rating from observation
blog.obs.name as obs_name, -- Name from observation
blog.obs."desc" as obs_desc, -- Description from observation
ST_Distance(blog.trails.geom, blog.obs.geom) AS dist_to_trail -- Calculate distance from observation to trail
FROM blog.trails
JOIN blog.obs
ON ST_DWithin(blog.trails.geom, blog.obs.geom, 200) -- Find all trails within 200m of observation points
ORDER BY obs_id, dist_to_trail ASC
),
-- Second CTE: Select only the nearest trail for each observation point
-- Uses DISTINCT ON to get single closest trail per observation
distinct_nearest AS (
SELECT
DISTINCT ON (obs_id)
obs_id,
trails_fid,
trails_osm_id,
trail_length,
obs_size,
severity_int,
obs_name, -- Add name
obs_desc, -- Add description
ST_LineLocatePoint(trails_geom, obs_geom) AS measure, -- Calculate relative position (0-1) along trail
ST_LineLocatePoint(trails_geom, obs_geom) * trail_length AS meas_length, -- Convert relative position to actual distance
dist_to_trail
FROM ordered_nearest
),
-- Third CTE: Calculate measurements and ranges for creating segments
-- Computes the actual positions where segments will start and end
events AS (
SELECT
obs_id,
trails_fid,
trails_osm_id,
trail_length,
obs_size,
severity_int,
obs_name, -- Add name
obs_desc, -- Add description
measure,
meas_length,
dist_to_trail,
1.0 / trail_length AS meas_per_m, -- Calculate conversion factor from meters to measure
GREATEST(0, LEAST(1, (meas_length - (obs_size/2)) / trail_length)) AS lower_m, -- Calculate normalized start point
GREATEST(0, LEAST(1, (meas_length + (obs_size/2)) / trail_length)) AS upper_m -- Calculate normalized end point
FROM distinct_nearest
),
-- Fourth CTE: Adjust measurements to ensure they stay within valid range (0-1)
-- Handles edge cases where segments would extend beyond trail endpoints
events_adjusted AS (
SELECT
obs_id,
trails_fid,
trails_osm_id,
trail_length,
obs_size,
severity_int,
obs_name, -- Add name
obs_desc, -- Add description
measure,
meas_length,
dist_to_trail,
meas_per_m,
lower_m,
upper_m,
GREATEST(0, LEAST(1, lower_m)) AS lower_meas, -- Ensure lower bound stays within [0,1]
GREATEST(0, LEAST(1, upper_m)) AS upper_meas -- Ensure upper bound stays within [0,1]
FROM events
),
-- Fifth CTE: Create points along the trail where observations are located
-- These represent the exact locations where observations intersect with trails
event_points AS (
SELECT
ST_LineInterpolatePoint(ST_GeometryN(blog.trails.geom, 1), GREATEST(0, LEAST(1, events_adjusted.measure))) AS geom, -- Ensure measure is within [0,1]
events_adjusted.obs_id,
events_adjusted.trails_fid,
events_adjusted.trails_osm_id,
events_adjusted.trail_length,
events_adjusted.measure,
events_adjusted.meas_length,
events_adjusted.obs_size,
events_adjusted.dist_to_trail,
events_adjusted.meas_per_m,
events_adjusted.lower_m,
events_adjusted.upper_m,
events_adjusted.lower_meas,
events_adjusted.upper_meas
FROM events_adjusted
JOIN blog.trails
ON (blog.trails.fid = events_adjusted.trails_fid)
),
-- Sixth CTE: Prepare trail geometries for final segmentation
-- Joins adjusted measurements back to trails to prepare for creating segments
cuts AS (
SELECT
events_adjusted.obs_id,
events_adjusted.trails_fid,
events_adjusted.lower_meas,
events_adjusted.upper_meas,
ST_GeometryN(trails.geom,1) as geom,
trails.osm_id,
trails.fid,
trails.id
FROM blog.trails
INNER JOIN events_adjusted
ON trails.fid=events_adjusted.trails_fid
ORDER BY events_adjusted.upper_meas
)
-- Final SELECT: Create the actual trail segments with all intermediate calculations and measurements
-- Uses ST_LineSubstring to cut trails into segments based on calculated measurements
-- Includes all intermediate attributes for analysis and verification
SELECT
ROW_NUMBER() OVER (ORDER BY c.obs_id, c.trails_fid) as segment_id, -- Generate unique sequential ID
ST_LineSubstring(c.geom, c.lower_meas, c.upper_meas) as geom, -- Create line segment between measured points
ST_Length(ST_LineSubstring(c.geom, c.lower_meas, c.upper_meas)) as segment_length_m, -- Calculate actual length of segment in meters
c.obs_id, -- Original observation ID
c.trails_fid, -- Original trail feature ID
c.osm_id as trails_osm_id, -- OpenStreetMap ID from trails
ea.severity_int, -- Severity rating from observation
ea.obs_name, -- Add name
ea.obs_desc, -- Add description
ea.trail_length, -- Total length of original trail
ea.measure, -- Relative position (0-1) along trail
ea.meas_length, -- Actual distance along trail
ea.obs_size, -- Size of observation in meters
ea.dist_to_trail, -- Distance from observation to trail
ea.meas_per_m, -- Conversion factor from meters to measure
ea.lower_m, -- Normalized start point before final adjustment
ea.upper_m, -- Normalized end point before final adjustment
c.lower_meas, -- Final start position of segment (0-1)
c.upper_meas -- Final end position of segment (0-1)
FROM cuts c
JOIN events_adjusted ea ON c.obs_id = ea.obs_id AND c.trails_fid = ea.trails_fid; -- Join to get intermediate calculations
Then add the index
-- Create a unique index on the materialized view using the new column name
CREATE UNIQUE INDEX mv_segments_segment_id_idx ON blog.mv_segments (segment_id);
and periodcally (maybe on a job) refresh the materialized view
-- Refresh the materialized view
REFRESH MATERIALIZED VIEW blog.mv_segments;
SELECT * FROM blog.mv_segments;
Usage
Here are some screens of these concepts in use in Qgis and PGAdmin4 (web version)
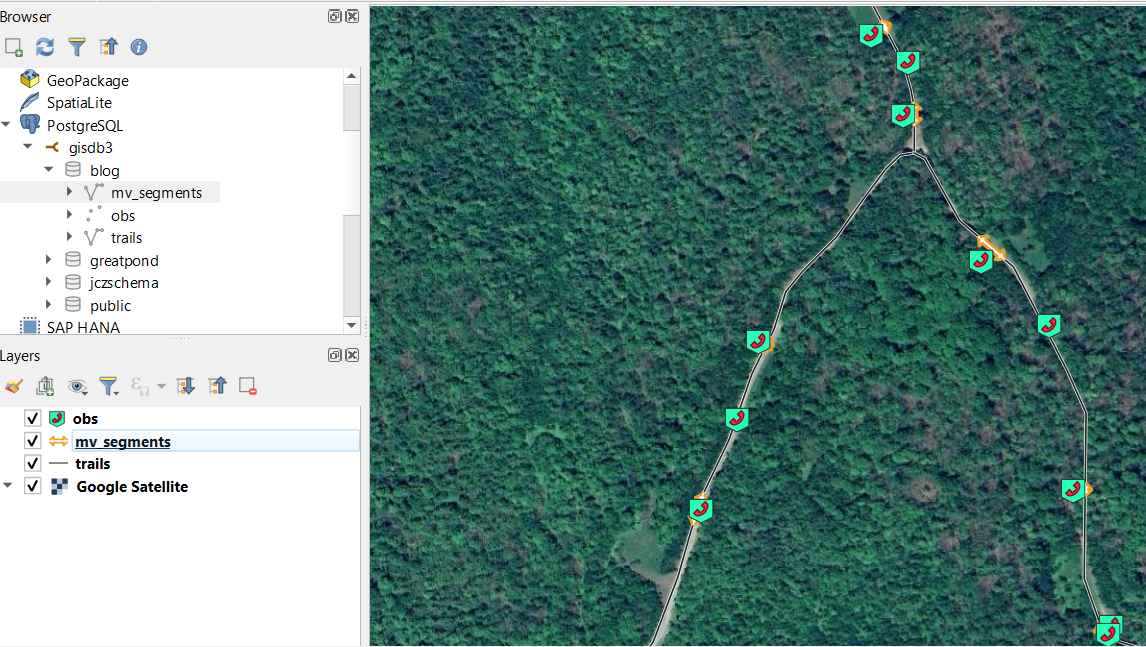
Figure 1. The basic entities we describe above. The top panel shows the blog schema with the resulting mv_segments materialized view with linstring outputs in it, and the inputs: obs point geometry table in PG and trails linestring table. These each correspond to their layers shown in the layer browser and the map. I’m on a new computer I had to restart on my symbologies (is there a way to share collections of Qgis synbols between computers?)
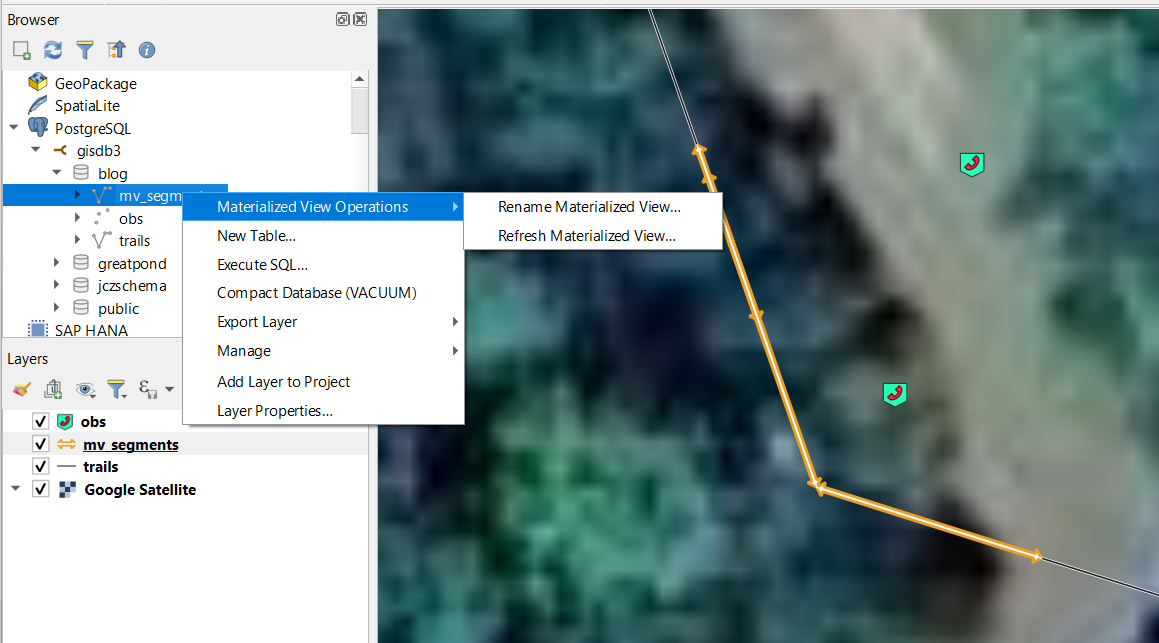
Figure 2. Little contextual flyout menu on the materialized view in Qgis allowing me to refresh it right from the comfort of my GIS. Qgis and PostGIS were kinda born together and have grown up together. Nice touch Devs!
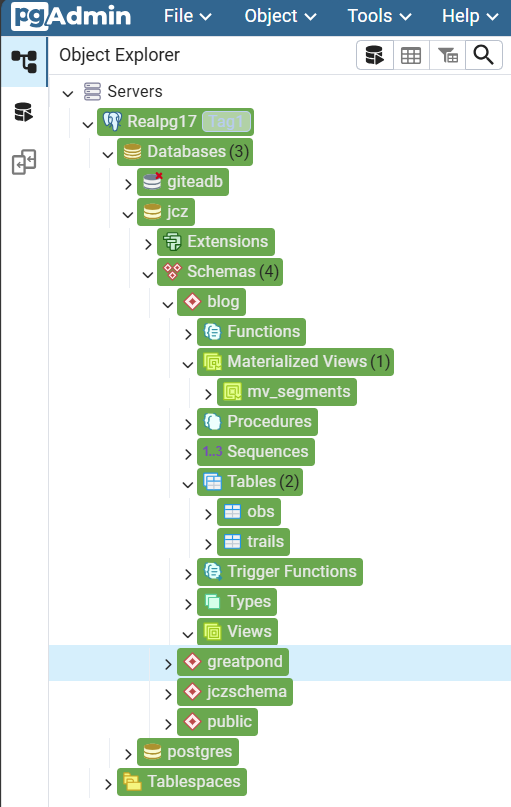
Figure 3. A slimmed down navigation pane from pgAdmin4 showing jcz/blog/mv_segments as database/schema/materialized view respectively.
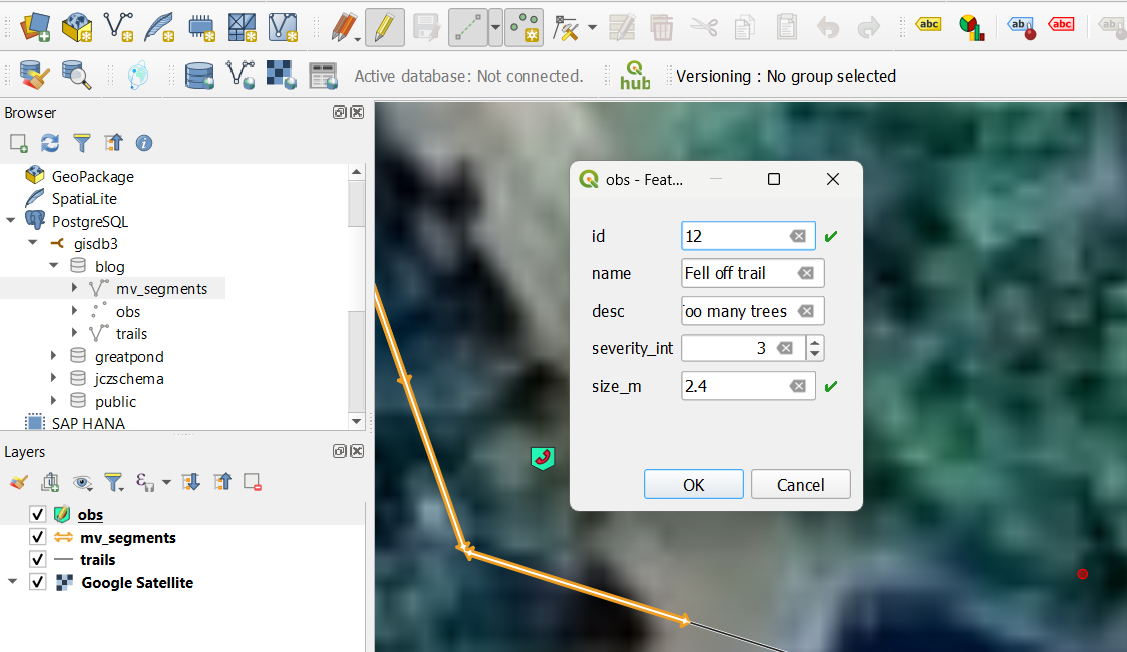
Figure 4. Editing the obs layer (table) in Qgis. I think I need to add a SERIAL to the primary key field ID so that it auto-populates and auto increments for me. Right now I’m typing into this field by hand.
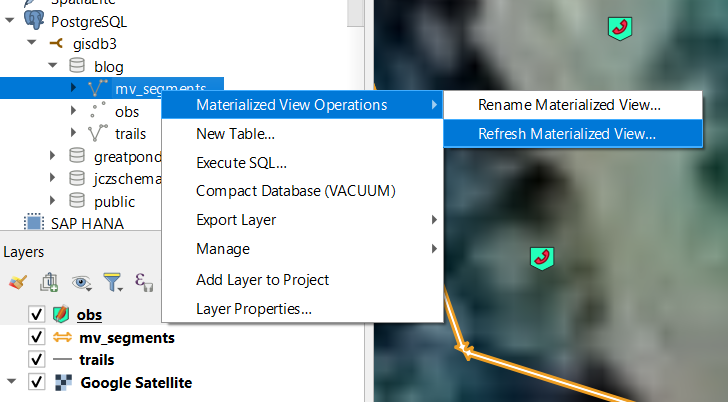
Figure 5. Just a reminder that if you are using Materialized Views, perhaps for better performance over a traditional view, that it needs to be refreshed to see the changes you made to the source tables.
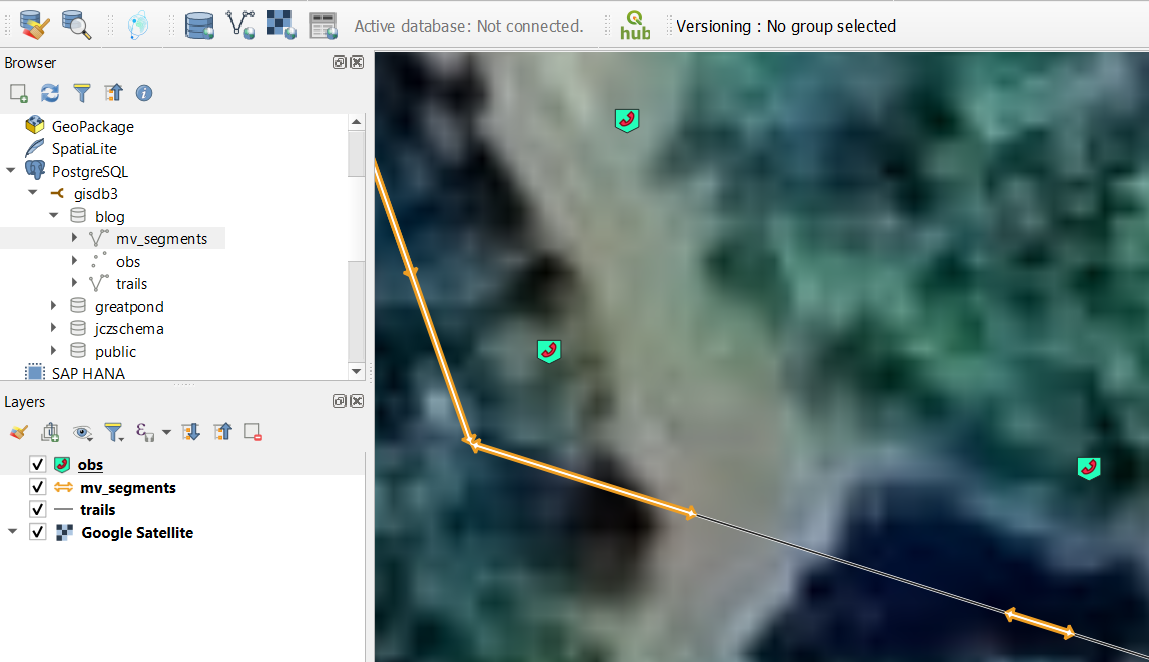
Figure 6. Example of what the segnments look like when the observation occurs near a straight section, and also near a corner with a node (endpoint). The observation near the corner has a size that spans the corner so the resulting event is broken into two. This view also highlights the snapping capability where the code will create the event segments on the nearest line to the observation point - which will never geometrically land on the line without snapping either in the field collection or in post-processing like this.
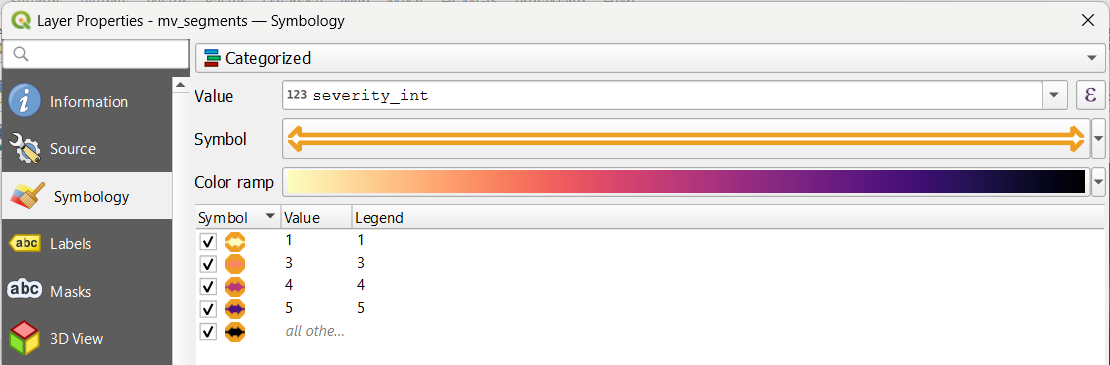
Figure 7. For visualization let’s change the symbology to show the severity of the problem. Of course this could be done better. I’m just having fun.
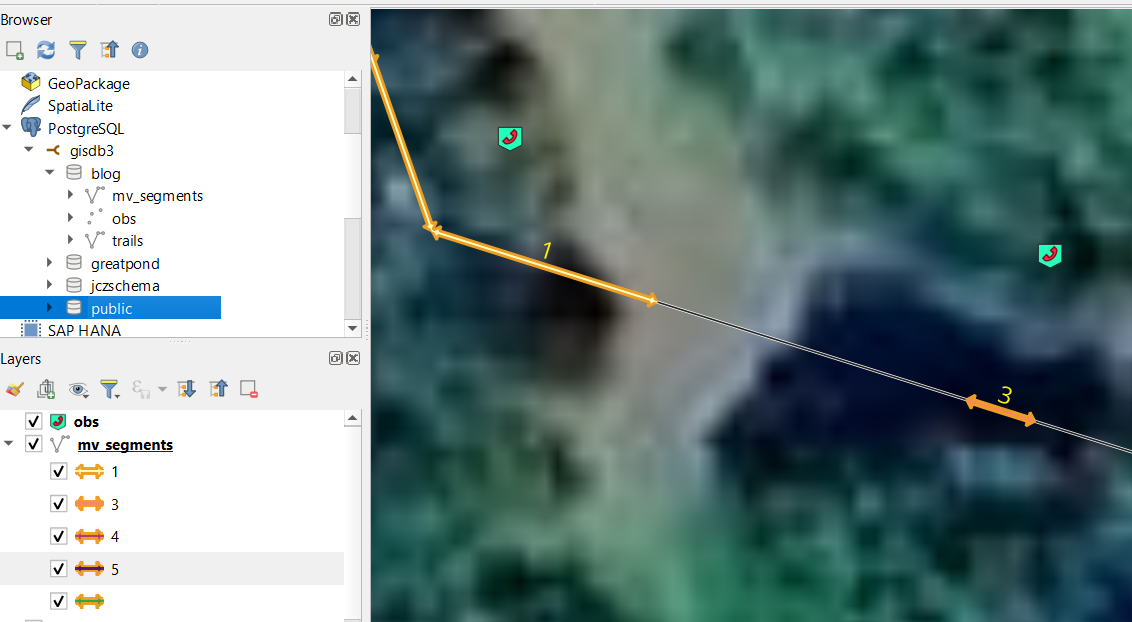
Figure 8. Updated the map view to demonstrate the new symbology and label the segments to prove we’re showing the severity integer value.
Here’s the sample aggregation prioritization query that needed some adjustments in order to run
WITH hotspots AS (
SELECT
ST_Union(ST_Buffer(s.geom, 100)) as cluster_geom, -- 100m buffer around segments
COUNT(*) as issue_count,
AVG(o.severity_int)::numeric(3,1) as avg_severity,
string_agg(o."desc", '; ') as issue_descriptions
FROM blog.mv_segments s
JOIN blog.obs o ON s.obs_id = o.id
GROUP BY ST_SnapToGrid(ST_Centroid(s.geom), 200)
HAVING COUNT(*) > 1
)
SELECT
issue_count,
ST_Area(cluster_geom) as affected_area,
avg_severity,
issue_descriptions,
(issue_count * avg_severity * ST_Area(cluster_geom))::integer as priority_score
FROM hotspots
ORDER BY priority_score DESC;
And some actual output. The Priority Score is just a simple multiplication of a few factors ` (issue_count * avg_severity * ST_Area(cluster_geom)`
| issue_count | affected_area | avg_severity | issue_descriptions | priority_score |
|---|---|---|---|---|
| 2 | 47438.313929242715 | NULL | NULL | NULL |
| 2 | 51812.377720770695 | NULL | NULL | NULL |
| 3 | 50552.78194914143 | 5.0 | NULL | 758292 |
| 4 | 61221.035901588555 | 2.7 | We’re going to need a bigger truck. Too many trees | 661187 |
Test for overlapping segments. This runs, but doesn’t seem to detect overlaps. Geomtry precision problem? Unlikely. That’s partly why we use linear ref.
SELECT
a.obs_id as seg1_id, -- First segment ID
b.obs_id as seg2_id, -- Second segment ID
-- Calculate the length of overlap in meters
ST_Length(ST_Intersection(a.geom, b.geom)) as overlap_length,
-- Get segment details for context
a.obs_size as seg1_size,
b.obs_size as seg2_size
FROM blog.mv_segments a
JOIN blog.mv_segments b ON ST_Overlaps(a.geom, b.geom)
WHERE a.obs_id < b.obs_id; -- Avoid duplicate pairs